Activation functions:
- To put in simple terms, an artificial neuron calculates the weighted sum of its inputs and adds a bias, as shown in the figure below by the net input.

-
Now the value of net input can be any anything from -inf to +inf. The neuron doesn’t really know how to bound to value and thus is not able to decide the firing pattern. Thus the activation function is an important part of an artificial neural network. They basically decide whether a neuron should be activated or not.
-
The activation function is a non-linear transformation that we do over the input before sending it to the next layer of neurons or finalizing it as output.
Comparing activation function ReLU vs Mish
ReLU ( Rectified Linear Unit )
- ReLU is a type of activation function. Mathematically, it is defined as y = max(0, x).

ReLU is the most commonly used activation function in neural networks, especially in CNNs. If you are unsure what activation function to use in your network, ReLU is usually a good first choice. ReLU is linear (identity) for all positive values, and zero for all negative values. This means that:
- It’s cheap to compute as there is no complicated math. The model can therefore take less time to train or run.
- It converges faster. Linearity means that the slope doesn’t plateau, or “saturate,” when x gets large. It doesn’t have the vanishing gradient problem suffered by other activation functions like sigmoid or tanh.
- Since ReLU is zero for all negative inputs, it’s likely for any given unit to not activate at all.
Mish is Self Regularized Non-Monotonic Activation Function
A new paper by Diganta Misra titled Mish: A Self Regularized Non-Monotonic Neural Activation Function introduces the AI world to a new deep learning activation function that shows improvements over both Swish (+.494%) and ReLU (+ 1.671%) on final accuracy.
- It is modified verion of swish activation function. Mathematically, it is defined as:


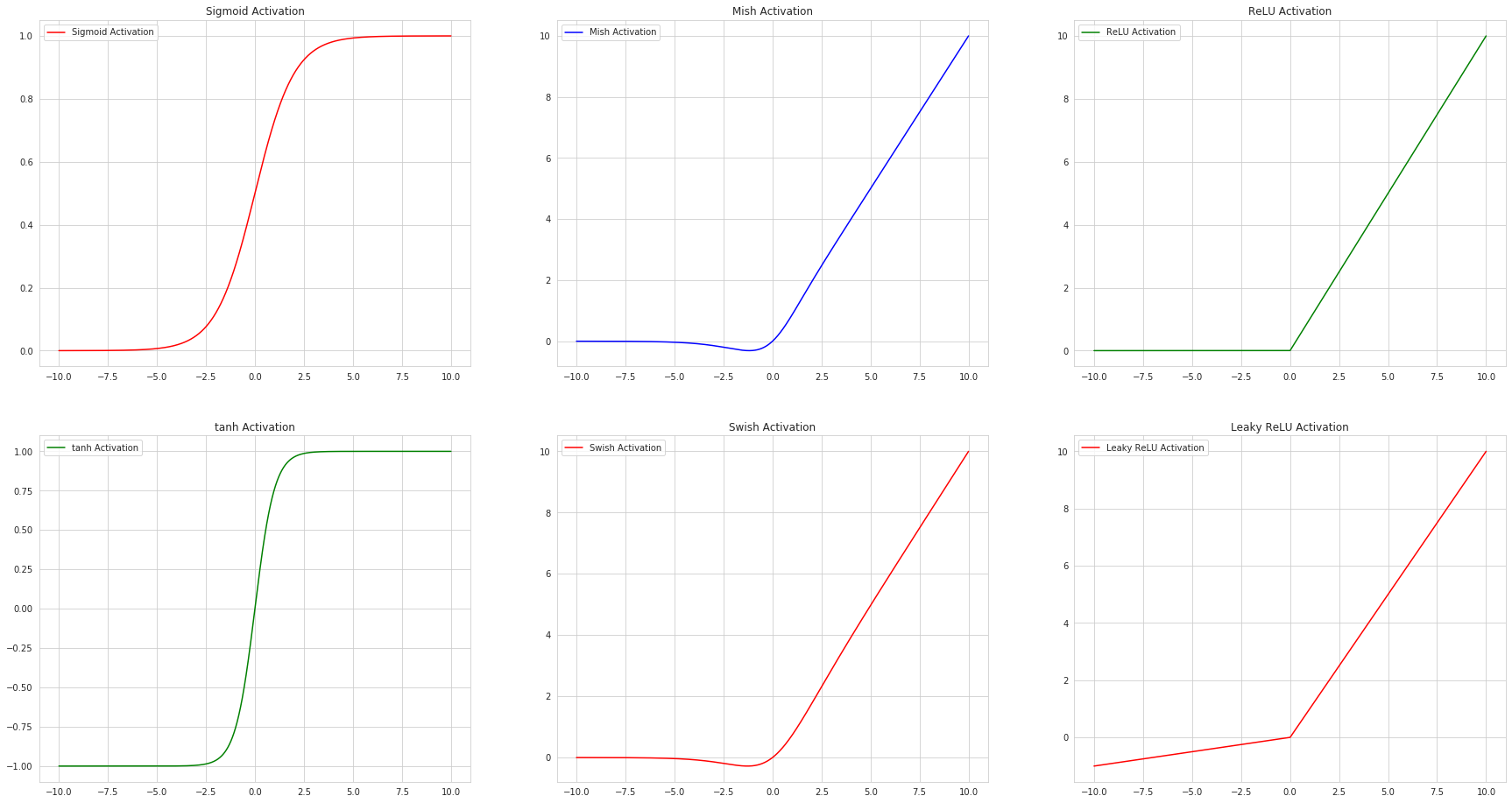
- Here is graph of six different activation functions:
I downloaded the pytorch implementation of Mish activation function of Diganta Mishra’s from a kaggle user Iafoos to compare it with ReLU on classification task of classic MNIST dataset.
-
Found true that it performs better.
-
But one of its down side is it’s computationally more expensive compared to ReLU which just takes max(0,x).
-
Below is the comparison time of 4 different Activation functions for 7 runs, 100k loops each.

Below are my findings and the Project Notebook:
- MNIST dataset has an unevenly distributed set of images.
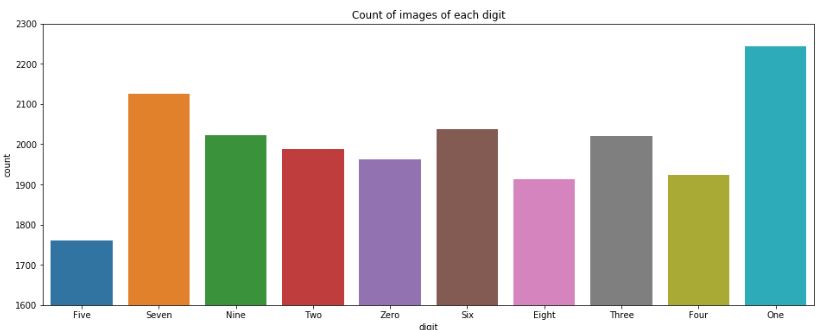
- Metrics I choose was macro average f1_score and accuracy.
- And defined two model one using ReLU activation and the other one using Mish Activation. Both models summary is given below:
Model with Mish.

Summary of Model with Mish.

Model with ReLU.

Summary of Model with ReLU.

I ran both the models with a learning rate of 1e-1 for 6 epochs. Below are the results:
Six epochs for Model with ReLU Activation function.

Six epochs for Model with Mish Activation function.

As one can see Model with Mish activation function gives better F1_score as well accuracy.
Credits and Refrences:
https://github.com/digantamisra98/Mish
https://www.kaggle.com/iafoss/mish-activation/
https://medium.com/@danqing/a-practical-guide-to-relu-b83ca804f1f7
https://www.geeksforgeeks.org/activation-functions/
Shoutout to:
- Fast.ai team for there fast.ai easy to use software to test model swiftly